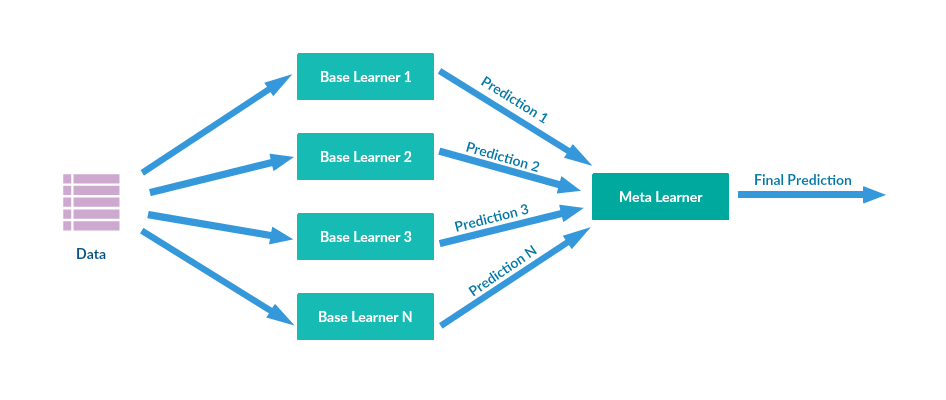
본 포스팅은 Boosting Algorithm에 관련된 내용입니다. 글에 적합한 이미지는 후에 차근차근 넣어보겠습니다.
Boosting Algorihtm
앙상블은 여러 모델을 사용하여 좋은 모델을 만드는 것을 목표로 하는 테크닉입니다. Kaggle 등의 DS Competition에서 높은 성적을 위해 많이 사용하는 방법이기도 합니다.
그중에서도 Boost 계열의 알고리즘은 약한(weak) 분류기를 많이 사용하여, 강한(Boost) 분류기를 만드는 것을 목표로 합니다. 이 중에서 흔히 사용하는 대표적인 알고리즘을 중심으로 하나씩 살펴보겠습니다.
간단한 모델인 앞의 두 모델은 매개변수까지 가볍게 살펴보고, 뒤의 알고리즘은 특징과 장/단점을 위주로 살펴보도록 하겠습니다.
- AdaBoost
- Gradient Boost Machine
- XGBoost
- LightGBM
- CatBoost
AdaBoost
서론
Adaptive Boosting의 줄임말인 AdaBoost는 꽤 오래된 모델입니다. 1996년에 Freund와 Schapire이 제안한 알고리즘입니다. 2003년에는 괴델상을 수상한 알고리즘이기도 합니다.
이 모델은 다른 학습 알고리즘(weak learner)의 결과물들에 가중치를 두어 더하는 방법으로 최종 모델을 만듭니다. 여러 알고리즘을 사용하여 일반화 성능이 뛰어나며, 매우 간단한 구현으로 가능하기에 효율성이 뛰어난 알고리즘입니다.
보통 속도나 성능적인 측면에서 desision Tree를 weak learner로 사용합니다.
좀 더 이해하기
AdaBoost는 다음과 같은 단계로 진행하게 됩니다.
- 각 weak 모델에서 학습할 데이터 선택
- 모든 데이터의 가중치 초기화
- 한 번 학습 후, error(ϵϵ ) 계산, 모델 별 가중치(αα ) 계산, 데이터 가중치(DD )를 갱신
- 오류가 0이 되거나, 약한 분류기 수가 최대치에 도달할 때까지 반복
- 최종적으로 각 분류기의 가중치를 고려한 선형합산으로 예측값 계산
과정을 보면 알 수 있듯이, 학습에 있어 error값으로 가중치들을 갱신합니다. 이 과정을 통해 이전 모델이 틀린 데이터를 보다 잘 구분할 수 있도록 가중치를 갱신합니다.
하지만 그런 이유로 이 모델은 noisy한 데이터나 이상치(outlier)가 있을 때 취약(sensitive)합니다.
Code로 보는 AdaBoost
scikit-learn Documentation
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_iris
from sklearn.ensemble import AdaBoostClassifier
# iris
X, y = # ~
clf = AdaBoostClassifier(n_estimators=100)
clf.fit(X, y)
clf.score(X, y)
기본적으로 base_estimator는 DecisionTreeClassifier를 사용하고 있고, n_estimators로 수를 조정합니다. (default값은 50입니다.)
learning rate는 default값으로 1. 을 사용합니다. 그 외에 ‘random_state’로 시드를 조정할 수 있습니다.
여기서 혼동할 수 있는 부분 중 하나는 learning_rate입니다. 대부분의 AdaBoost 문서에는 learning rate가 포함될 부분이 없어보입니다.
저는 그 답을 StackExchange에서 찾았습니다. 구체적인 수식은 링크를 타고 보시면 될 것 같고, learning_rate과 n_estimators에 대한 내용만 덧붙이자면
- learning_rate L을 줄인다면
- L은 가중치를 갱신하는 데 쓰이는 αα 값에 붙는 상수(1이하 양의 실수)입니다.
- 이는 가중치 갱신의 크기/스케일을 줄입니다.
- 그렇기에 weak classifier의 결정 경계들(decision boundaries)간의 차이가 적습니다. (모델의 단순화)
- 반복 횟수 M을 늘린다면
- 사용하는 weak classifier의 수를 늘고, 최종적으로 이를 선형으로 더해야합니다.
- 그렇기에 분류기의 결정 경계가 더욱 다양해지고 복잡해집니다.
이런 이유로 L과 M은 trade-off 관계라고 생각할 수 있습니다. 그렇기에 둘을 잘 조정하여 사용하는 것이 이 알고리즘의 핵심입니다.
수 많은 변형
여기서 변형된 알고리즘으로는 다음과 같은 알고리즘이 있습니다. 더 많이 있지만, wiki의 상위 2항목만 소개하면 다음과 같습니다.
| Algorithm | Description |
|---|---|
| Real AdaBoost | 기본적인 Adaboost는 분류기의 결과를 {1, -1}로 사용하는데 이를 실수로 표현하여 확률값으로 계산가능 |
| LogitBoost | Logistic Regression을 활용한 AdaBoost |
이제 이런 AdaBoost를 시작으로 만들어진 알고리즘을 아래에서 보도록 합시다.
Gradient Boosting
서론
GBM(Gradient Boosting) 이라고도 부르며, Friedman이 2001년에 소개한 알고리즘입니다. 다른 명칭으로는 MART(Multiple Additive Regression Trees) 또는 GBRT (Gradient Boosted Regression Trees)이 있습니다.
좀 더 이해하기
AdaBoost와 같은 순서로 진행합니다. 단 모델의 가중치(DD )를 계산하는 방식에서 Gradient Descent를 이용하여 파라미터를 구합니다.
AdaBoost에서는 모델 가중치를 고려한 선형합으로 최종 predictions을 구합니다. 그렇다면 이 모델 가중치 선형 합 연산을 하나의 식으로 본다면 어떨까요? 모델에 따른 최적의 가중치를 Gradient decent로 구해서 보다 최적화된 결과를 얻고자 하는 것이 GBM의 특징입니다.
하지만 GBM은 greedy algorithm이고, 과적합(overfitting)이 빠르게 된다는 단점이 있습니다. 그렇기에 일부 사항에 제약을 두어 모델의 일반화 성능을 향상시킬 수 있습니다.
다음은 어떤 방식으로 일반화시킬 수 있는지 봅시다.
Code로 보는 GBM
scikit-learn Documentation
보다 나은 모델을 위한 방법을 코드와 함께 알아보도록 하겠습니다. GBM에 있어 매개변수는 크게 3개로 나눌 수 있습니다.
- Tree-Specific : 개별 트리 관련
- Boosting : boosting 연산 관련
- Other : 그 외
나눠서 봅시다. 아래 Reference에도 적어두었지만, 기본적으로 parameter를 어떤 식으로 튜닝할 수 있는지 좋은 글이 있으니 함께 보면 좋을 것 같습니다. GBM 기반의 알고리즘에서 보통 공통적으로 사용하는 매개변수이므로 간단하게 정리해보았습니다.
Tree-Specific
| parameter | description |
|---|---|
max_depth |
트리의 최대 깊이입니다. decision tree가 깊어질 수록 모델은 복잡해지고, 모델은 과적합될 가능성이 큽니다. 그렇기에 깊이를 얕게 하는 것이 좋습니다. (제가 참고한 글에서는 4-8이라고 하네요.) |
max_leaf_nodes |
노드의 최대 개수입니다. 최종적으로 decision tree에서 만들어지는 노드들의 수를 한정합니다. |
min_samples_split |
leaf의 분할 가능 최소 개수입니다. 분할 기준을 제한하여 모델의 복잡도를 줄입니다. |
min_sample_leaf |
leaf 노드가 되기 위한 최소 개수입니다. 바로 위의 매개변수와 잘 조정하여 사용합니다. |
min_weight_fraction_leaf |
위와 유사하지만, 이는 전체 개수에서 비율로 조정합니다. 위의 매개변수와 동시 사용은 불가합니다. |
max_features |
나누는 기준이 되는 feature의 개수입니다. sqrt 정도 사용하라고 합니다. 값에 따라 과적합이 발생할 수 있습니다. |
Boosting
| parameter | description |
|---|---|
n_estimators |
트리의 개수입니다. 모델에 트리가 너무 많게 되면 학습 속도가 너무 느리게 됩니다. 개수에 따른 성능 향상이 크게 없다면 수를 더 이상 늘릴 필요는 없습니다. |
learning_rate |
일반적으로 값이 낮을수록 좋지만, 낮은 만큼 많은 수의 트리가 필요하고, 계산 비용이 많이 드니 조정해야합니다. |
subsample |
개별 트리는 데이터를 부분적으로만 사용하여, 각 트리간의 상관도를 줄입니다. 랜덤하게 데이터를 선택하여 쓰고, 그렇기에 Stochastic Gradient Boost라는 명칭을 씁니다. ~0.8 정도에서 fine tuning을 하면 됩니다. |
그 외의 변인은 따로 설명은 하지 않겠습니다. 궁금하신 분은 공식 문서를 확인하는 것을 추천합니다.
이제부터 본격적으로 Competition에서 많이 사용하는 3대 Boosting 알고리즘을 살펴봅시다. 구체적인 매개변수는 다루지 않을 예정입니다. (왜냐면 거의 100개에 가까운 매개변수를 정리하는 건 너무 비효율적이니까요.)
XGBoost
서론
2014년, Tianqi Chen이 GBM을 기반으로 만든 알고리즘입니다. 만들고 바로 유명해진 것은 아니고 2016년에 Kaggle에서 Higgs Machine Learning Challenge에서 본인이 만든 알고리즘을 사용하여 우승했고, 이후 친구의 제안을 받아 python으로 만들고 논문도 publish하였다고 합니다. 후기
로직 자체는 매우 복잡합니다. 그렇기에 구체적 알고리즘을 알기보다는 기존 GBM과의 차이나 장단점을 위주로 보도록 하겠습니다. 성능이 얼마나 뛰어나면 eXtream GBM일까요.
좀 더 이해하기
기존 GBM에서 시스템 최적화와 알고리즘 성능 향상은 다음과 같이 진행했습니다.
- 시스템 최적화에는 병렬화(Parallerlization), 가지치기(Tree Prunning), 하드웨어 최적화(Hardware Optimization)이 있습니다.
- 알고리즘 성능 향상에는
- Lasso나 Ridge를 통한 정규화
- missing value의 패턴을 찾아 효율적으로 처리 (결측값은 모두 제외하고 분할, 그 후에 loss가 제일 적은 곳에 할당)
- weighted Quantile Sketch algorithm을 사용한 효율적인 분할
- 교차 검증을 통한 일반화
위에서 언급한 방법 덕분에 기존 GBM에 비해 월등히 속도가 빠르고, 훈련시간을 줄였으며, 보다 일반화된 모델을 얻을 수 있게 되었습니다. 또한 위에서 언급한 바와 같이 missing value를 따로 처리하지 않아도 된다는 장점이 있습니다. 또한 병렬화를 덕분에 GPU를 사용할 수 있게 되었습니다.
XGBoost는 scikit-learn이 아닌 xgboost 패키지가 따로 존재합니다. 또한 조정가능한 매개변수가 지나치게 많기 때문에 공식 문서를 보며 차차 세부 튜닝하는 것을 추천합니다.
LightGBM
서론
2016년에 발표되어 XGBoost를 이은 GBM 기반의 모델입니다. 최근 Kaggle에서 가장 많이 우승한 알고리즘이기도 합니다. Microsoft에서 발표한 알고리즘입니다. 그렇기에 패키지도 따로 있습니다.
기존에 GBM이 DFS와 같이 leaf에서 더 깊은 leaf를 생성했다면(level wise/depth wise), LightGBM은 BFS와 같이 같은 level의 leaf를 추가적으로 생성합니다.(leaf-wise) 좀 더 쉽게 표현하면, 기존에는 세로로 자라는 나무였다면 LightGBM은 가로로 자라는 나무입니다.
좀 더 이해하기
LightGBM은 다음과 같은 장점이 있습니다.
- 빠른 교육 속도 및 높은 효율성 : LightGBM은 히스토그램 기반 알고리즘을 사용합니다.
- 기존에는 분할을 위해 모든 데이터를 확인했지만, LightGBM은 히스토그램으로 근사치를 측정
- local voting과 global voting의 사용으로 병렬화에서 소모되는 communication 연산 축소
- voting 결과로 분할할 수 있는 feature가 2개 선택 -> 매우 빠름
- XGBoost와 같이 Missing Value 무시
- 메모리 사용량 감소 : 기존 GBM보다 적은 메모리를 사용합니다.
- 정확도 : leaf-wise 방식을 사용하여 복잡한 모델을 만들고, 더욱 높은 정확도를 만듭니다. 과적합될 가능성이 있지만 max_depth 등의 매개변수로 조정할 수 있습니다.
- 대용량 데이터 세트와의 호환성 : XGBoost와 비교하여 속도가 빠르고(2~10배 정도), 유사한 성능을 냅니다.
- GPU 사용 가능
물론 단점도 존재합니다. 과적합이 쉽게 되는 모델이기에 적은 데이터셋이 아닌 10000개 이상의 데이터셋이 있을 때 적합한 알고리즘입니다.
XGBoost와 다르게 범주형(Categorical)도 따로 처리할 수 있게 되어있습니다. int로 변환하여 제공해야하긴 하지만 one-hot encoding이 아닌 다른 방식으로 범주형 feature를 관리합니다. (코드에서 categorical_feature로 넘겨줄 수 있습니다.)
LightGBM에서 parameter tuning에 대한 좋은 글이 있어 공유합니다.
CatBoost
제가 이전 앙상블 시리즈 글을 쓸 당시에는 자료가 논문 외에는 크게 없었는데, 이제는 좀 많네요!
서론
가장 최근(2017.06)에 발표되었고, 급부상중인 알고리즘인 CatBoost입니다. Categorical을 다루는 알고리즘이라 CatBoost입니다. 빠른 속도, 정확도 향상, 범주형 데이터 특화 등 여러 장점을 앞세운 알고리즘입니다.
대표적으로 ordered boosting의 구현, categorical feature 처리가 핵심인 알고리즘으로 좀 더 구체적으로 알아보겠습니다.
좀 더 이해하기
Categorical Feature Processing
-
기존의 GBM은 One-Hot 인코딩을 사용하여 범주형 특성을 다뤘습니다. 이런 One-Hot 인코딩은 전처리 단계에서 진행할 수도 있고, 훈련 중에서도 진행할 수 있는데 CatBoost는 훈련과 함께 이를 진행합니다. 기본적으로 categorical feature의 값이 두 종류라면 One-Hot을 진행합니다. 그 외에는
one_hot_max_sizeparameter를 통해 사용할 수 있습니다. -
그 외에도 다음과 같은 방법을 사용하여 Categorical을 다룹니다. CatBoost는 해당 category의 level마다 바로 이전 data points의 target value들만 고려합니다.(이 과정에서 이전은 time을 의미합니다. CatBoost에서는 순서를 위해 가상의 시간 순서를 만듭니다.) 그 과정에서 기댓값에 따라 categorical value의 값을 결정합니다. (이 방식에서는 첫 값을 얻을 수 없기에 prial과 가중치 a값을 도입한다.)
-
범주형 간의 상관관계가 있는 경우를 대비하여 자체적으로 Feature를 Combination해서 만들어줍니다. NP-Hard 문제이기에 Greedy하게 Tree로 만들어, 새로운 Feature를 수치화하여 사용합니다.
-
수치는 다른 GBM과 같이 수치로 취급됩니다.
cat_feature로 범주로 넘겨줄 수도 있습니다.
Ordered Boosting
기존의 알고리즘은 이전에 사용했던 데이터를 다시 재사용하여 과적합이 쉽게 되었습니다. (target leackage 발생)
그렇기에 CatBoost는 첫 번째 학습된 잔차로, 두 번째 모델을 만들고, 그 값에서 graient로 업데이트하고 ~ 를 반복하여 모델을 만듭니다. 이 방법은 target이 아닌 관측된 기록에만 의존하기에 leackage를 막을 수 있습니다.
이 방법을 사용하기 위해서는 메모리 관리가 필수인데, CatBoost는 균형잡힌 Tree 모델을 사용했습니다. 모델을 확장하며 위의 leaf를 cut-off하는 방식입니다. 이런 이진 모델의 특징 덕분에 leaf node의 idx만 가지고 value를 불러낼 수 있어 매우 빠르게 테스트를 할 수 있다고 합니다.
또한 랜덤화된 순열을 한 번만 사용하면 기존 데이터보다 분산이 큰 결과만 나오게 되므로, 각 부스팅 단계마다 다른 순열을 사용합니다.
장단점
정리하면 다음과 같습니다.
- missing data를 처리 해주지않는다.
- 대신 categorical에 특화되어 있다.
- 수치형 데이터가 많다면 LightGBM보다 느리다.
- 하지만 그래도 비슷하게 빠르다.
- 다른 GBM에 비해 overfitting이 적다.
Wrapped Up…
상위 3개의 알고리즘을 사용하는 것은 옳은 선택입니다. 하지만 다음을 고려하면 좋을 것 같습니다.
- 완전한 정답은 없다.
- XGBoost는 느리다.
- CatBoost는 범주형 데이터가 많을 때 좋다.
- GBM 기반은 overfitting을 방지하기 위한 튜닝이 중요하다.
다들 Keep Going 합시다!!
느낀점
- 이런 모델을 만들 수 있는 사람이 되고 싶다는 생각이 드는 공부였습니다.
- 반나절 정도 읽고 정리한 것 같은데 정리가 조금 마음에 안드네요. 읽은 것보다 양이 너무 적기도 하고..
- ‘글을 알고리즘 별로 쓸 걸…;이라는 생각을 했습니다. (보다 상세한 코드 적용을 위한 글은 개별로 써야겠습니다.)
Reference
AdaBoost
- Wikipedia : AdaBoost
- Boosting algorithm: AdaBoost
GBM
- A Gentle Introduction to the Gradient Boosting Algorithm for Machine Learning
- Complete Machine Learning Guide to Parameter Tuning in Gradient Boosting (GBM) in Python
XGBoost
- XGBoost: A Scalable Tree Boosting System
- XGBoost Official Documentation
- XGBoost Algorithm: Long May She Reign!
LightGBM
- LightGBM: A Highly Efficient Gradient Boosting Decision Tree
- Which algorithm takes the crown: Light GBM vs XGBOOST?
- LightGBM and XGBoost Explained
CatBoost
- CatBoost: unbiased boosting with categorical features
- CatBoost: gradient boosting with categorical features support
- Hoonki90님 블로그 : CatBoost
- Mastering The New Generation of Gradient Boosting
- What’s so special about CatBoost?
- catboost github
ALL
( 윗 부분에 출처가 붙여지지 않아 하단부에 붙입니다. )
출처 : https://subinium.github.io/introduction-to-ensemble-2-boosting/
'데이터사이언스 > MachineLearning' 카테고리의 다른 글
| Ensemble 1/2 (앙상블) (0) | 2020.04.23 |
|---|